Este es un entrenamiento avanzado por lo que se parte de la base que se cuenta con una idea general a nivel de instalación y configuración de Exchange.
En complemento a los videos de entrenamiento se incluye información teórica, en parte para reforzar conceptos manejados en las lecciones y en parte para hacer mención a componentes que aunque en la diaria no tengamos que manejar es importante saber que existen.
En definitiva, te recomiendo revisar aunque sea superficialmente el material teórico de la lección, ya sea antes o después de ver los videos. Intenté minimizar la cantidad de información hasta dejar únicamente la de mayor utilidad.
Así que empezamos.
Acceso no autorizado. Para acceder al contenido complete el registro haciendo clic aquí.
Qué es un DAG?
Un DAG (Database Availability Group) es una agrupación lógica de servidores con el rol de Mailbox.
Básicamente es un contenedor lógico al cual agregamos servidores con Exchange. El DAG proporciona la infraestructura necesaria para replicar y coordinar la activación de bases de datos.
Podemos agregar hasta 16 servidores a un DAG de Exchange y es posible tener múltiples DAG dentro de la organización.
Importante: No se puede combinar versiones de Exchange dentro de un mismo DAG (pero es posible tener múltiples DAG con distintas versiones de Exchange.
En qué momento se crea el DAG?
El DAG se crea manualmente luego de instalar Exchange, es decir que el proceso de instalación es el mismo independientemente de si el servidor va a estar o no dentro de un DAG.
Para qué agregamos servidores a un DAG?
Porque es el único modo de poder replicar una base de datos en más de un servidor.
Para qué querría replicar una base de datos de Exchange?
Por redundancia, en lugar de tener una única copia de una base de datos podríamos tener hasta 16 si así lo quisiéramos. El mínimo para alta disponibilidad serían 2 copias, pero dependiendo del requerimiento específico cuantas réplicas precisemos.
Importa el nombre del DAG?
El nombre es para identificar un DAG ya que entre otras cosas podríamos tener más de uno. Los usuarios no ven este nombre y no se debe incluir en el certificado. Por fuera de que los usuarios no lo usen muchas veces aplicaciones como por ejemplo de backup se conectan utilizando el nombre del DAG.
En general uno encuentra nombres como DAG01, DAG1, DAG2013, DAG2016, etc. En definitiva, el nombre no es importante mientras nos permita identificar con claridad cuál es la finalidad del DAG.
Qué relación tiene un DAG y un «cluster de Exchange»?
Antiguamente se hablaba de “cluster de Exchange”, esto viene de la época en la que Exchange utilizaba un modelo de cluster donde teníamos por ejemplos 2 servidores (o nodos) conectados a un almacenamiento compartido.
Este modelo tenía varias desventajas, siendo la principal el punto de falla que implica el almacenamiento compartido. Por más que tuviéramos múltiples nodos, si falla el almacenamiento nos quedamos sin cluster, es decir sin Exchange.
Este sistema se mantuvo hasta Exchange 2007 (aunque en esta versión se introdujeron varias opciones adicionales).
A partir de Exchange 2010, cuando hablamos de alta disponibilidad implica la utilización de un DAG.
En un DAG no utilizamos almacenamiento compartido, cada servidor tiene su propio almacenamiento. En este caso podemos usar discos internos o algún tipo de almacenamiento externo.
Exchange usa la característica de cluster de Windows?
Si bien no se utilizan recursos de cluster específicos a Exchange, el DAG tiene dependencias sobre el servicio de cluster como por ejemplo para monitorear el estado de los servidores mediante heartbeats (básicamente “latidos” que indican si un servidor esta accesible) y para mantener quorum.
Estos componentes de cluster le proporcionan información necesaria a Exchange para evaluar si se requiere tomar una acción o no. Específicamente a nivel de Exchange el componente que coordina estas actividades es el Active Manager.
En definitiva, respecto a DAG y cluster, es común escuchar que hablen de un cluster de Exchange cuando en realidad se hace referencia a un DAG. Lo que debemos tener bien claro es que siempre que se habla de alta disponibilidad en Exchange (a partir de 2010) hablamos de DAG.
Activo / Pasivo
En un DAG no tenemos servidores “activos” o “pasivos”, un servidor nunca esta 100% pasivo. El concepto aplica a nivel de base de datos, no podemos tener una copia de una base activa en más de un servidor a la vez (de suceder esto estaríamos frente a un problema para nada menor).
La base activa es a la cual se terminan conectando los usuarios (a través de los componentes de acceso de clientes), estas bases figuran en las interfaces administrativas como “mounted” o montadas. Por otro lado tenemos las bases pasivas (en un estado normal las vemos como «healthy» o saludable), estas son copias de la base activa y en cualquier momento producto de una falla o una acción administrativa pueden pasar de pasiva a activa.
Las bases deben estar distribuidas en distintos servidores, es decir que no podríamos tener más de una copia de una misma base en un mismo servidor.
Tipos de DAG
En Exchange 2010 y antes del CU4 de Exchange 2013 solo teníamos un tipo de DAG, a lo que de ahora en más me voy a referir como “DAG tradicional”. Este tipo tiene mayor dependencia en el servicio de cluster de Windows y por ejemplo agrega recursos como nombre de red (network name) y dirección IP específica para el DAG. Este es el modelo tradicional de DAG y podríamos denominarlo como DAG con punto de acceso administrativo al cluster (CAAP: Cluster Access Administrative Point). En la demo de Exchange 2013 vemos como crear este tipo de DAG.
A partir de Exchange 2013 SP1 (CU4) sobre Windows 2012 R2 es posible crear un DAG sin un punto de acceso administrativo al cluster. Esto es recomendable en caso de que no haya ninguna incompatibilidad con aplicaciones de terceros.
Este modelo también tiene dependencias sobre el servicio de cluster pero no requiere recursos como nombre y dirección IP. Tampoco requiere un CNO (Cluster Name Object) en Active Directory. En la demo con Exchange 2016 vemos como configurar este tipo de DAG.
De nuevo.. qué es el CNO?
A partir de Windows Server 2012 uno de los requerimientos para la creación de un DAG es pre crear una cuenta de CNO. El CNO es una cuenta de máquina que creamos en Active Directory con el nombre del DAG, deshabilitada y con permisos especiales asignados para Exchange.
Este CNO solo lo precisamos en el caso de usar el modelo tradicional de DAG.
Qué tipo de DAG uso?
DAG sin punto de acceso administrativo al cluster (modelo nuevo), esto reduce la complejidad de la solución.
Cuando es necesario crear un DAG de tipo tradicional?
Hoy por hoy en la mayoría de los casos no es necesario ir por el modelo tradicional. Sin embargo, debemos tener en cuenta que pueden haber incompatibilidades entre el nuevo modelo y alguna aplicación de terceros, por ejemplo de backup.
En definitiva antes de definir qué tipo de DAG crear debemos confirmar que no hayan incompatibilidades con otras aplicaciones. La recomendación en este caso es consultar con el proveedor de la solución de terceros.
Después de crear el DAG que se debe hacer?
Cuando creamos el DAG se crea un contenedor vacío a nivel de configuración en Active Directory, de por si este no aporta nada.
Es decir que crear el DAG no implica que ya tenemos alta disponibilidad.
Una vez con el DAG creado ya podemos empezar a agregar servidores con el rol de mailbox, esto automáticamente instala las características de failover clustering y realiza toda la configuración necesaria.
A tener en consideración que si se usa el modelo nuevo de DAG no tenemos interfaz gráfica para acceder a la configuración del cluster, en este caso deberíamos utilizar Powershell. Por fuera de esto, en principio toda actividad sobre el DAG debe ser manejada a través de interfaces administrativas de Exchange salvo casos avanzados de troubleshooting.
Ya con los servidores agregados al DAG estamos en condiciones de comenzar a agregar réplicas de las bases de datos.
Qué debo verificar antes de comenzar a replicar las bases?
Lo primero es ver la ubicación de las bases de datos y logs de transacciones. De forma predeterminada al instalar Exchange se crea una base de datos en la misma ruta donde se instaló el producto.
Teniendo esto en cuenta lo que debemos hacer es crear unidades adicionales, lo que en principio va a depender del dimensionamiento de la solución. Por fuera de si se precisan 1 o más unidades, estas deben ser formateadas en 64k (y 64k no es el valor predeterminado de Windows). Esto es muy importante desde el punto de vista del rendimiento.
Otro tema es que cada servidor que vaya a alojar una réplica de una base de datos debe tener las unidades necesarias. Por ejemplo si creamos una base “DB1” en la unidad “E:” es necesario que cada servidor que vaya a alojar una réplica tenga una unidad “E:”. Esto se debe a que cuando agregamos una réplica no podemos indicar donde la queremos ubicar. En definitiva la base DB1 va a ser ubicada en la unidad “E” de cada servidor con una réplica.
En resumen, antes de empezar a configurar réplicas debemos:
- Formatear las unidades que alojen bases de datos o logs en 64k
- Ubicar la base de datos en la ruta definitiva
- Verificar que cada servidor que aloje una réplica cuente con las unidades necesarias
Cómo replican las bases de datos?
En primera instancia cuando agregamos una réplica en otro servidor comienza un proceso conocido como sembrado o “seeding” de la base de datos, esto básicamente es una copia por lo que debemos considerar que el sembrado inicial dependiendo del tamaño de la base de datos puede tardar. Este es otro de los motivos por los cuales es mejor tener múltiples bases “chicas” en lugar de pocas “grandes”.
Una vez realizado el sembrado inicial, las bases de datos se mantienen sincronizadas en base a replicación asincrónica de logs (log shipping), estos logs tienen un tamaño exacto de 1MB.
Para esto se utiliza el puerto 64327 TCP por lo que si hay firewalls entre servidores de un DAG es necesario asegurarse de que este puerto este habilitado.
Preferencia de activación de copias de base de datos
Cada copia de una base tiene un valor de preferencia de activación.
En el servidor donde se crea la base de datos automáticamente esta preferencia se setea en 1. Donde agregamos la primer réplica se setea en 2 y así de forma incremental. Independientemente de esto, es posible modificar la preferencia en cualquier momento.
Para qué sirve la preferencia de activación?
La preferencia de activación indica en que servidor sería ideal que se encuentre montada (activa) la base.
Frente a un problema, cómo se coordina la activación de bases de datos?
La coordinación de la activación de bases de datos utiliza un componente que se llama Active Manager.
En un servidor miembro de un DAG, Active Manager puede operar con el rol de PAM (Primary Active Manager) o de SAM (Standby Active Manager), en cualquiera de los casos el componente monitorea la salud de las bases y llegado el caso contacta al PAM (primario) para que tome una acción (ej. un failover).
Adicionalmente el Active Manager es consultado por otros componentes de la infraestructura como por ejemplo servicios asociados a la función de acceso de clientes para obtener información sobre bases y eventualmente hacer de proxy hacia el servidor que se encuentre con la base activa.
Cómo saber cuál es el servidor que actúa como PAM?
El servidor con el rol de PAM es el que tiene el default cluster resource group. En caso de que el servidor con el rol de PAM falle, otro servidor miembro del DAG sería “promovido” de SAM a PAM de forma automática.
En general, no es necesario interactuar directamente con este componente.
En base a qué criterio Active Manager activa una base de datos?
Active Manager al tener que tomar una decisión sobre qué base activar cuenta con una serie de criterios predefinidos como por ejemplo cantidad de logs por copiar o aplicar, preferencia de activación de bases y salud general del servidor entre otros, este proceso se conoce como BCSS o Best Copy and Server Selection (selección del mejor servidor y copia de base).
Dentro de este proceso también se toma en cuenta el valor del parámetro AutoDatabaseMountDial configurado a nivel de servidor de mailbox. De forma predeterminada este parámetro habilita a activar una base de datos incluso si faltan 6 o menos logs, este valor se llama Good Availability y en general aunque falten algunos logs la información es recuperada automáticamente mediante otros mecanismos como por ejemplo Safety Net como vamos a ver más adelante.
En general no es necesario modificar el valor de AutoDatabaseMountDial.
Cómo se selecciona que base de datos activar?
Frente a un escenario de falla de una base con múltiples copias, Active Manager corre el proceso BCSS y en base a una serie de condiciones prioriza las réplicas candidatas a ser activas.
Dentro de las condiciones a chequear encontramos por ejemplo cola de logs por replicar (Copy queue length), cola de aplicación de logs (Replay Queue Length), estado del índice de las bases y preferencia de activación entre otros.
Una vez seleccionada una réplica, Active Manager corre un proceso denominado ACLL (Attempt Copy Last Logs) que intenta copiar logs que puedan faltar por replicar desde el origen (o sea la base que falló).
Independientemente de logs que puedan faltar por replicar, bloqueos de activación administrativos sobre las bases, etc, si el DAG no tiene Quorum, las bases serán desmontadas y no podrán ser activadas hasta que no se obtenga la mayoría de votos.
A qué se refiere el término “Copy queue length”?
El valor de copy queue length nos indica la cantidad de logs que falta copiar para estar actualizados en relación a la copia activa.
Y replay queue length?
En este caso los logs ya copiaron pero no aplicaron en la base de datos. Por ejemplo en el caso de copias con retraso (lagged copies) los logs se copian pero quedan sin aplicar en la base por el tiempo de retraso definido (esto lo vemos más adelante).
Switchover o failover?
En general cuando se activa una base en otro servidor uno escucha hablar de failover, pero técnicamente quizás sea un switchover.
Dependiendo de si la activación de la base es producto de una acción administrativa o de una falla en el sistema cual sea el término más apropiado.
Switchover hace referencia a que un administrador inicio el proceso, mientras que failover indica que hubo un problema que derivó en la activación de la base en otro servidor.
Qué es quorum y qué relación tiene con el servidor testigo?
El concepto de quorum es fundamental, sin quorum las bases de datos no pueden montar, o sea que sin quorum no hay correo.
La configuración de quorum determina la cantidad de fallas que puede soportar un cluster antes de detener la operativa. Para esto se utiliza un sistema de votos y dependiendo la cantidad de nodos (par o impar) el modelo de quorum a utilizar.
Por qué varia el modelo de quorum en función a si la cantidad de nodos es par o impar?
Supongamos lo siguiente, se juntan 3 amigos a comer y no saben que pedir por lo que deciden hacer una votación (asumamos que deben ponerse de acuerdo en qué comer); 1 quiere pizza y los otros 2 empanadas. En este caso claramente ganan las empanadas.
Ahora supongamos que son 4 amigos, 2 quieren pizza y 2 empanadas, en este caso es un empate. Cómo resolvemos esto? En el caso de que la cantidad de votos sea par es posible que se dé la situación donde un 50% quiera una cosa y el otro 50% quiera otra, esto cuando la cantidad es impar no es problema.
Volviendo a Exchange, cuando la cantidad de nodos es par necesitamos algo que permita desempatar, para esto usamos un servidor “testigo” o FSW (File Share Witness). De esta manera incluso teniendo una cantidad par de servidores siempre es posible llegar a una mayoría de votos. Para tener quorum debemos tener al menos la mitad + 1 de los votos.
Este servidor testigo es simplemente un servidor Windows que tiene una carpeta compartida y permisos especiales para Exchange. Normalmente no se utiliza, pero si el DAG está a un voto de perder quorum uno de los nodos hace un lock SMB al testigo (en otras palabras se conecta a un archivo dentro de la carpeta del testigo).
El hecho de que el cluster requiera mantener quorum para continuar con la operativa previene que por ejemplo por un problema de red una base quede activa en más de un servidor a la vez (más adelante vamos a ver que aparte debemos complementar con otra configuración).
Modelos de quorum
En Exchange podemos usar 2 modelos de quorum dependiendo de la cantidad de nodos. Este modelo se configura automáticamente en base a la cantidad de servidores.
DAG con cantidad par de nodos
Un DAG con una cantidad par de nodos utiliza un modelo denominado Node and File Share Majority, es decir mayoría de nodos incluyendo un servidor testigo (dependiendo de la interfaz puede figurar como “FileShareWitness”). En este modo se utiliza este servidor extra que no puede ser uno de los miembros del DAG.
El testigo no requiere Exchange instalado y es básicamente un servidor Windows con una carpeta compartida. Esta carpeta no ocupa espacio ni requiere nada en particular a nivel de recursos, prácticamente no se usa.
El servidor del DAG que se conecte a este recurso tiene un voto con más peso (podríamos decir que vale x2).
En definitiva, para mantener quorum se debe tener la mitad + 1 de los votos y cada servidor tiene un voto, el que se conecta al testigo cuenta como uno adicional.
DAG con cantidad impar de nodos
Un DAG con cantidad impar de nodos utiliza el modelo Node Majority o mayoría de nodos (en algunas interfaces se ve como “NoWitness”). En este caso no es necesario utilizar el testigo para desempatar porque no se puede dar la situación donde la mitad de los nodos estén operativos y la otra mitad no. Supongamos el caso de un DAG con 3 nodos, si se cae 1 nodo se mantiene quorum porque mantiene la mayoría, si se caen 2 se pierde el quorum.
Por otro lado en caso de tener una cantidad par por ejemplo 2 nodos en un sitio y 2 en otro, si se cae el enlace entre ambos sitios, donde queda la base activa? en este caso como es una cantidad par de nodos va a quedar donde se encuentre el FSW (File Share Witness). Por este motivo en este caso deberíamos tener ubicado el testigo en el sitio principal.
Quorum dinámico / Testigo dinámico
En Windows Server 2012 se introduce un nuevo modelo de quorum «dynamic quorum» o quorum dinámico.
El quorum dinámico viene habilitado de forma predeterminada y lo que hace es administrar los votos asignados a cada nodo del DAG, esto lo hace en base al estado del servidor, un servidor puede estar en línea o fuera de línea (caído).
Al quedar un nodo fuera de servicio, este pierde el voto asignado para el cálculo de quorum. Cuando vuelva a estar en línea lo recupera, esto de forma «dinámica».
Qué logramos con esto?
El cluster dinámicamente puede incrementar o disminuir la cantidad total de votos necesarios para mantener quorum.
En lugar de tener en cuenta el voto de todos los nodos que formaron el DAG lo que considera es el voto de todos los servidores que se encuentran en línea, esto nos habilita escenarios donde perdemos más de la mitad de los nodos sin perder quorum.
Para que esto funcione las fallas o apagados de los servidores deben ser secuenciales, la condición es que en todo momento se mantenga quorum. Por ejemplo si tenemos 5 servidores no podríamos perder 3 en simultaneo, pero podríamos perder 1, luego otro y luego otro perdiendo finalmente 3 pero siempre secuencial manteniendo quorum.
En Windows Server 2012 R2 esto se complementa con la característica “Dynamic witness” o testigo dinámico. Esto lo que agrega es la posibilidad de ajustar dinámicamente el voto del servidor testigo en base a la cantidad de nodos activos en el DAG.
Es importante saber que existen estas características y que vienen habilitadas de forma predeterminado pero no hay necesidad de modificar nada a este nivel.
Redes en DAG
Una red dentro de un DAG es una colección de subredes que Exchange utiliza para tráfico de replicación o MAPI (red de clientes podríamos decir). Cuando recién salió el DAG en Exchange 2010 existía la recomendación de separar el tráfico de replicación del de clientes y en muchos casos puede tener sentido seguir esta práctica.
Hoy por hoy en la mayoría de los casos no es necesario separar el tráfico ya que seguramente con una tarjeta de red sea suficiente para soportar todo. De cualquier modo esto va a depender del escenario específico, de no existir un requerimiento en particular siempre ir por la opción más simple, en este caso utilizar una única placa.
En caso de optar por separar el tráfico, de forma predeterminada a partir de Exchange 2013 se maneja la configuración de forma automática. Para que esto funcione correctamente debemos configurar las placas de red de forma apropiada, en particular debemos configurar la placa de red dedicada a replicación del siguiente modo:
- Desmarcar “Client for Microsoft Networks”
- Desmarcar “File and printer sharing…”
- No configurar DNS ni WINS
- Desmarcar la opción de registrar en DNS
- No utilizar Default Gateway (si existen servidores en distintas subredes utilizar rutas estáticas)
- Cambiar la prioridad de la tarjeta para que sea menor al de la placa principal
Por fuera de que configuremos una placa dedicada a replicación si esta red se encuentra fuera de servicio Exchange ignora el hecho de que esta sea una red dedicada y replica por cualquier placa que se encuentre disponible.
Compresión y Cifrado
La comunicación de red entre los miembros de un DAG soporta compresión y cifrado del tráfico. Ambas características se encuentran habilitadas de forma predeterminada cuando los nodos están en subredes diferentes. Estos valores pueden ser modificados.
Para compresión se utiliza XPRESS (implementación de Microsoft del algoritmo LZ77) y en caso de cifrado SSP (Kerberos Security Support Provider).
Sobre autoreseed
Este concepto se introduce en Exchange 2013 y en implementaciones muy grandes con niveles muy maduros a nivel de operaciones puede ser una buena opción.
Básicamente la característica de autoreseed habilita a configurar volúmenes dedicados al auto sembrado de bases de datos en caso de que un disco falle. Así como podríamos tener discos de “reserva” en el caso de RAID, podemos tener discos de reserva, disponibles para que frente a una falla se dispare un proceso de autosembrado.
Esta característica está muy orientada a servicios de nube o a empresas donde se cuenta con múltiples servidores, físicos, sin RAID y con 3 o 4 copias de una misma base de datos.
La realidad es que no aplica a la mayoría de las organizaciones.
Alcanza con configurar el DAG y replicar bases de datos para tener alta disponibilidad?
El DAG y la replicación de bases nos garantiza redundancia a este nivel, es decir las bases de datos se encontrarían en un esquema de alta disponibilidad, por lo que frente a un problema los datos van a estar replicados en al menos otro servidor.
El tema acá es, qué pasa con los clientes? Cómo se conectan a estas bases de datos replicadas?
O sea que teniendo las bases replicadas no es suficiente para garantizar que los usuarios puedan conectarse a estas bases.
Los usuarios se conectan a través de los componentes de acceso de clientes. Esto en Exchange 2013 es un rol como vimos en la primer lección, mientras que en Exchange 2016 es un conjunto de servicios.
Sobre el acceso de clientes
Los usuarios para conectarse al correo deben conectarse a un servidor con la función de Acceso de clientes, esto puede ser manejado de forma manual modificando reglas en firewall o registros DNS o idealmente de forma automática.
Para todo esto partimos de la base de que tenemos al menos 2 servidores que incluyan los componentes de Client Access.
Si queremos automatizar el proceso debemos configurar el acceso de clientes para utilizar algún tipo de mecanismo de balanceo, esto puede ser logrado mediante:
- DNS Round Robin (múltiples registros con un mismo nombre apuntando a distintas IP). Esta es una solución económica ya que no implica ningún costo adicional, simplemente agregar registros a la zona DNS. Adicionalmente los clientes HTTP tienen lógica para resolver el registro a múltiples IP y en caso de que un registro no responda después de una X cantidad de segundos intentar con el siguiente. Por fuera de esto si un servidor responde y el servicio no está funcionando correctamente vamos a tener clientes que quizás funcionen bien y otros que no. En el laboratorio usamos este tipo de configuración y en muchos clientes puede ser una configuración valida.
- HLB (balanceador por hardware o virtual appliance). Esto también se puede encontrar con otros nombres como por ejemplo Application Delivery Controller. Basicamente es un dispositivo virtual o físico que se encuentra ubicado delante de los servidores con la función de acceso de clientes y distribuye las conexiones. En este caso los clientes resuelven el nombre asociado a los servicios de Exchange a una IP virtual configurada en el balanceador. El cliente establece la conexión al balanceador el cual utiliza algún tipo de algoritmo de balanceo dependiendo de su configuración.
- NLB (servicio de balanceo de Windows). Este mecanismo era soportado en Exchange 2010 y 2013 pero no en Exchange 2016. Independientemente de la versión de Exchange, NLB no es recomendado para entornos productivos. Si igualmente queremos utilizarlo debemos tener los roles separados (cosa que en Exchange 2016 no podemos hacer). Esto se debe a que el servicio de cluster (dependencia del DAG) es incompatible con el servicio de NLB.
A nivel de balanceo de clientes, cuál es el mecanismo recomendado?
La recomendación es utilizar un balanceador virtual o físico.
A este nivel se soporta balanceo en capa 4 (capa de transporte en modelo OSI) o en capa 7 (capa de aplicación).
Un balanceador que trabaja en capa 4 no está al tanto del tipo de tráfico que balancea, el balanceador pasa la conexión en base a una IP y puerto, no tiene conocimiento de que servicio específico es el que se está utilizando. Por ejemplo OWA utiliza el puerto 443, Activesync también y lo mismo con todos los servicios HTTPS.
Se podría dar el caso que un servidor esté funcionando bien para OWA pero no para Activesync, frente a esto el balanceador va a seguir distribuyendo el tráfico porque el puerto responde.
Un balanceador que trabaja en capa 7 es más inteligente ya que tiene conocimiento del tipo de tráfico que pasa, puede inspeccionar el contenido y ofrece funcionalidad más avanzada que en los de capa 4.
En adición, se aprovechan mejor las características asociadas a Managed Availability en Exchange 2013 y 2016. Esta característica monitorea los componentes y servicios de Exchange y en base a la información obtenida realiza algún tipo de acción orientada a la recuperación automática del servicio.
Por fuera de que la recomendación sea usar un balanceador (o múltiples balanceadores), esto puede variar. Trabajo con clientes muy grandes incluyendo Bancos que por ejemplo utilizan DAG con Exchange 2013, con los roles separados y NLB de Windows configurado en los Client Access. Es esta la recomendación?
No, no es la recomendación, pero muchas veces se continúan prácticas que en algún momento fueron recomendadas aunque actualmente ya no lo sean.
Por otro lado pueden haber restricciones a nivel de presupuesto por lo que se decida no ir por la opción de usar un balanceador y en este caso la opción que nos queda es utilizar DNS Round Robin, esto en Exchange 2010 no era una buena idea, pero en Exchange 2013 y mejor aún en Exchange 2016 puede funcionar muy bien.
Lo otro es que debemos definir el mecanismo de balanceo interno y externo, lo que en general puede implicar una combinación de balanceador a nivel interno y múltiples registros en un DNS externo. Por ejemplo internamente el registro “mail” apunta a la IP del balanceador, mientras que externamente tenemos 2 registros “mail”; 1 apuntando a una IP pública en el datacenter principal y otro apuntando a una IP pública de un datacenter alternativo.
Por ahora dejo esto tema por acá, a medida que avance el entrenamiento vamos a ir entrando en más detalle.
Más allá del mecanismo de balanceo, cómo se conectan los clientes?
Una vez que el cliente se conecta al servidor, el servicio de acceso de clientes acepta la conexión, la autentica y luego hace de proxy al servidor con la base activa o quizás una redirección si se encuentra en otro sitio.
Los pasos serían:
- El cliente resuelve el nombre de acceso a la IP virtual del balanceador (si se usa DNS RR el nombre se resolvería a las IP de los distintos servidores)
- De existir un balanceador este utiliza el algoritmo configurado para distribuir la carga entre los servidores
- El cliente es autenticado y el servicio de CAS consulta Active Directory para ver la ubicación del buzón del usuario
- El servicio de acceso de clientes hace proxy al servidor apropiado utilizando el mismo protocolo con el que accedió originalmente el usuario. En algún caso también podría redireccionar a otro sitio.
Especial atención al utilizar split DNS
Al usar zonas en split, si olvidamos incluir alguno de los registros externos en la zona interna vamos a encontrarnos con que los usuarios internos no pueden acceder al recurso mientras que desde internet funciona correctamente.
Esto se debe a que cuando creamos la zona interna, el servidor pasa a ser autoritativo para esta, si un cliente le solicita resolver www.aprendiendoexchange.com y el servidor no tiene el registro, este no va a salir a consultar uno externo sino que va a devolver una respuesta autoritativa indicando que el recurso no existe.
Para evitar esta situación, lo ideal sería actualizar la zona interna (en split) con los mismos registros que la externa pero si esto representa una carga significativa es posible utilizar lo que se conoce como pinpoint DNS, donde en lugar de crear una zona interna aprendiendoexchange.com lo que hacemos es crear una zona mail.aprendiendoexchange.com, autodiscover.aprendiendoexchange.com, etc, únicamente con la IP que se resuelve al servidor Exchange. Esto en general funciona bien en empresas con pocos servidores que quizás no tienen un administrador dedicado como para mantener la zona en split.
En definitiva hay que tener especial cuidado al utilizar una zona DNS en split ya que si no mantenemos la zona con los mismos registros que en la externa nos podemos encontrar con problemas cuando se consulta internamente.
En cuanto a transporte …
A nivel de transporte con Exchange en Alta Disponibilidad combinamos 2 características:
- Shadow Redundancy. Asegura la entrega de correos mediante la creación de copias redundantes de cada mensaje en tránsito. Frente a una falla en el servidor que aceptó originalmente el mensaje se solicita la entrega desde otro servidor.
- Safety Net. El principal objetivo en este caso es el de recuperar la mayor cantidad de datos posibles luego de un failover de tipo “lossy”. La palabra en inglés quizás no diga mucho pero en la documentación oficial podemos leer sobre “lossy failover”. Esto indica que hubo un failover y la base se montó en un servidor que no tenía todos los logs copiados, a pesar de esto pudo montar ya que la cantidad de logs que faltaban se encontraba debajo del valor del parámetro “AutoDatabaseMountDial” (6 logs por defecto). A pesar de que falten logs los datos pueden ser recuperados mediante Safety Net.
Ambas características se encuentran habilitadas de forma predeterminada. En el caso de Safety Net si no modificamos nada almacena los últimos 2 días de correo.
Correo externo
Por fuera de las características incorporadas en el producto para redundancia, tenemos que resolver el caso del correo externo. Esto requiere configuración adicional.
Dado que es un entrenamiento avanzado no voy a mencionar las básicas de envío / recepción de correo pero vamos a abordar 2 casos bien puntuales:
- Entrada de correo mediante la creación de múltiples registros MX
- Salida de correo mediante múltiples servidores configurados en un conector de envío
Entrada de correo
Para redundancia a nivel de entrada de correo en general vamos a manejar la creación de múltiples registros MX. Los registros MX apuntan a un registro de tipo “A” que a su vez se resuelven a una dirección IP.
Entonces por ejemplo si tenemos 2 enlaces podríamos:
- Crear 2 registros “A”; 1 que se resuelva a uno de los enlaces y otro que se resuelva al otro
- Crear 2 registros “MX”, cada uno a puntando a un registro “A” diferente
- Configurar la preferencia de los registros MX con el mismo valor de tal forma de balancear la entrada de correo. Opcionalmente podríamos configurar un MX como primario y otro como secundario por si falla el primer enlace (esto lo hacemos configurando valores distintos a nivel de preferencia)
En definitiva, en principio a nivel de Exchange no debemos hacer nada, toda la configuración es a nivel de la zona externa en DNS.
Salida de correo
Para la salida de correo externo debemos configurar conectores en Exchange. En este caso tenemos 2 opciones:
- Crear 1 conector y agregar múltiples servidores como orígen de transporte. Esto permite el balanceo de la salida de correo en múltiples servidores.
- Crear varios conectores, configurar distintos origenes de transporte. En este caso el conector a usar va a variar en función al costo que configuremos en cada uno de ellos.
En general configuramos 1 conector para el sitio principal, múltiples servidores como posible origen y si tenemos un sitio de contingencia configuramos otro conector separado (esto lo vamos a ver más adelante).
Qué es Managed Availability?
En Exchange 2013 se introduce Managed Availability, esto proporciona características de monitoreo y mecanismos de recuperación automáticos orientados a minimizar el impacto en el usuario frente a un eventual problema en el sistema.
Este monitoreo activo se integra con las características de alta disponibilidad.
Managed Availability está diseñado para la detección y recuperación lo más rápido posible teniendo en cuenta que el foco no es identificar la raíz del problema sino que la recuperación del servicio.
Managed Availability es un proceso interno que se ejecuta en cada servidor con Exchange 2013 / 2016 y está continuamente tomando muestras de salud del sistema. Si se detecta algún problema, dentro de lo posible se repara y en los casos que no se pueda se escala a un administrador, por ejemplo mediante el registro de un evento en el event viewer. En adición puede complementarse con SCOM (System Center Operations Manager).
Para realizar las pruebas utiliza buzones de sistema dedicados o Health mailboxes, estos buzones son creados automáticamente.
Dentro de lo que es Managed Availability tenemos 3 componentes que están trabajando de forma continua:
- El primero se llama Probe, que básicamente sería el responsable de tomar medidas y recolectar datos del sistema. Esto sería en plural ya que existen múltiples Probes.
- Estos resultados pasan al componente de monitoreo que es el que contiene toda la lógica necesaria a nivel de lo que se considera saludable. Este componente en base a una serie de patrones evalúa la salud del sistema.
- Por último tenemos Responders, los cuales son responsables de tomar medidas orientadas a la recuperación o escalación dependiendo del caso. Si un componente no se encuentra saludable la primer acción es intentar recuperarlo lo que podría implicar múltiples acciones adicionales, por ejemplo reiniciar un Application Pool de Internet Information Services, reiniciar un servicio e incluso reiniciar el servidor. Si el sistema no es capaz de recuperarse se escala mediante una notificación en el log de eventos.
Con esto llegamos al final del material teórico para esta lección, sin dudas esta es la lección que implica más lectura.
A tener en consideración que la información sobre DNS y certificados si bien no es exclusiva al funcionamiento de Alta Disponibilidad y Contingencia es crítica para una correcta configuración de un entorno con Exchange.
Por otro lado se incluyeron varios conceptos como Managed Availability y Autoreseed que no son vitales para implementar Exchange pero que es importante saber que existen. Esto mismo aplica a otros temas, en definitiva, si en la parte práctica no vemos un tema es porque o viene correctamente configurado de forma predeterminada o porque no aplica a la mayoría de las implementaciones.
Configuración de DAG en Exchange
Acceso no autorizado. Para acceder al contenido complete el registro haciendo clic aquí.
En esta lección comenzamos con la parte práctica del entrenamiento, en primer instancia configuramos el entorno con Exchange 2013 y posteriormente el entorno con Exchange 2016.
Estos entornos se encuentran 100% desconectados, es decir que por un lado tenemos un ambiente con Exchange 2013 y por otro uno similar con Exchange 2016, la idea es validar los procedimientos en ambos casos y ver que son casi idénticos.
Ambiente de laboratorio para el entrenamiento en Alta Disponibilidad
En ambos ambientes contamos con 2 sitios; Principal y Contingencia. Para conectar estos sitios tenemos un equipo funcionando como router. Este equipo también va a funcionar para emular un DNS externo más adelante en el entrenamiento.
A nivel de sistema operativo utilizamos Windows Server 2012 R2 en el caso de servidores. En cuanto a los clientes utilizamos Windows 10 con Outlook 2013.
Si bien a nivel de servidor manejamos los mismos nombres de host, para hacer más evidente cuando trabajamos con un entorno u otro usamos nombres diferentes a nivel de Active Directory.
Ambiente 2013
- FQDN del dominio: AprendiendoExchange.local
- Netbios: AEXCHANGE
- Nombre público: AprendiendoExchange.com
Entorno con Exchange 2013

Ambiente 2016
- FQDN del dominio: Horuscs.local
- Netbios: HORUSCS
- Nombre público: Horuscs.com
Entorno con Exchange 2016

Punto de partida
El entrenamiento parte de la base de que los servidores con Exchange se encuentran instalados de forma predeterminada, es decir que se siguió el asistente de instalación y no se realizó ningún tipo de configuración.
Para la instalación se siguieron las instrucciones detalladas en módulos anteriores sobre instalación y configuración de Exchange.
Dado que comenzamos viendo el caso de Alta Disponibilidad nos vamos a enfocar en la instalación del sitio Principal:
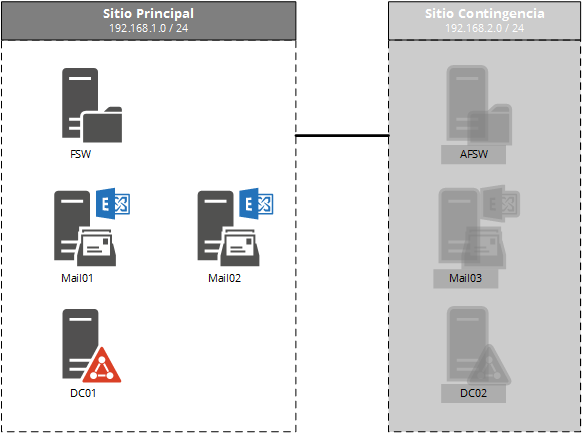
Escenario Objetivo
El objetivo es lograr el tipo de implementación más comun a nivel de Alta Disponibilidad en el sitio Principal.
Qué implica este escenario?
El escenario más común a este nivel en Clientes implica la creación de un único DAG compuesto por al menos 2 servidores con Exchange y 1 servidor con la función de testigo (FSW). En el caso del ambiente de laboratorio utilizamos el controlador de dominio (DC) como FSW y esto es únicamente por un tema de recursos, en producción debemos utilizar un servidor que no sea miembro del DAG y que no sea DC.
En cuanto al tipo de DAG, este puede ser tradicional (con punto de acceso al cluster) o sin punto de acceso (no CAAP, nuevo modelo). En el caso del laboratorio configuramos el entorno con Exchange 2013 con el tipo de DAG tradicional y el caso de Exchange 2016 con el nuevo modelo. Esto lo hacemos de esta manera para ver como configurar ambos casos, la realidad es que podríamos utilizar Exchange 2013 con el nuevo modelo y 2016 con el modelo tradicional.
Lo que hay que tener en mente es que esto varía dependiendo de si hay algún tipo de incompatibilidad con el nuevo modelo, en general esto puede presentarse con la aplicación que utilicemos para backups. De no haber incompatibilidad iríamos siempre por el nuevo modelo.
Diagrama de arquitectura del escenario objetivo
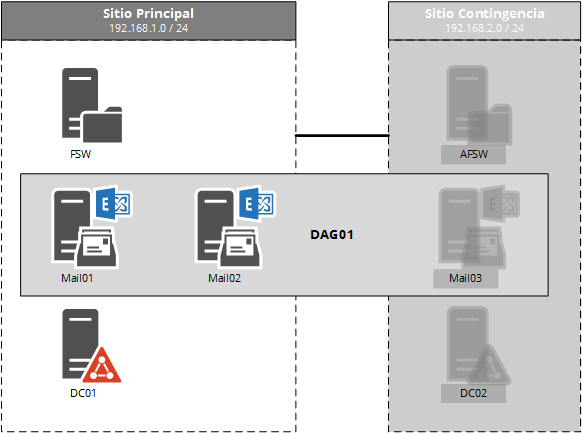
Bases de datos
En cuanto a las bases de datos vamos a contar con 2 replicadas y utilizando una preferencia de activación que habilite a distribuir fácilmente la carga entre los servidores, en este caso la base DB1 activa en un servidor y la DB2 en otro.
Esto en Clientes teniendo en cuenta las limitaciones de la versión Standard de Exchange (máximo 5 bases montadas) puede variar. Conceptualmente es lo mismo tener 1 base o tener 10.
Como vemos en el laboratorio lo primero que hacemos con las bases es renombrarlas ya que el nombre predeterminado no nos dice mucho. Para renombrar las bases debemos realizar 2 tareas:
- Cambiar nombre a nivel de configuración
- Cambiar nombre de archivo EDB (en este caso con el mismo comando cambiamos también la ubicación de base y logs)
Antiguamente existía la recomendación de separar en distintas unidades las bases de los logs de transacciones y esto aun podría aplicar en el caso por ejemplo de servidores «stand alone», es decir sin alta disponibilidad.
Esta recomendación se daba por 2 temas; 1 de recuperación, si perdemos el disco de las bases aun podríamos tener el de los logs, si perdemos el de los logs nos queda el de las bases, otro motivo era rendimiento, las bases de datos son principalmente de lectura, mientras que los logs son principalmente de escritura secuencial. Por este motivo también encontramos distintas recomendaciones a nivel de RAID, etc.
Actualmente en las nuevas de versiones de Exchange los requerimientos a nivel de IOPS de disco (operaciones de entrada / salida por segundo) han disminuido tanto que normalmente no es necesario hacer una separación por cuestiones de rendimiento. En adición si contamos con DAG tampoco sería necesario a nivel de recuperación ya que tendríamos la información replicada.
En definitiva, en el laboratorio ubicamos en la misma unidad bases y logs. Lo más importante en este sentido es formatear correctamente la unidad: en 64k.
A nivel de sistema de archivos podemos utilizar NTFS o ReFS, en el caso del lab usamos NTFS ya que es el sistema que vamos a encontrar más frecuentemente.
Acceso de clientes
Este tema es donde encuentro mayor confusión en Clientes, la mayoría de los errores a nivel de configuración vienen por el lado de la configuración de los directorios virtuales, autodiscover, DNS y certificados. Esto es algo que aplica a cualquier tipo de implementación independientemente de si es con alta disponibilidad o no.
Cuando esto no esta bien configurado tenemos usuarios con problemas para conectarse o por ejemplo con errores de certificado.
Balanceo
Como vimos en la lección de conceptos hay varias formas de balancear el acceso de clientes. En general esto se reduce a 2:
- HLB (o virtual appliance)
- DNS Round Robin
Independientemente del mecanismo la recomendación implica crear una zona DNS en split (ver lección de conceptos).
En el laboratorio utilizamos DNS RR por lo que configuramos 2 registros con el mismo nombre, cada uno apuntando a una IP diferente. Esto lo hacemos para el registro «mail» y para el registro «autodiscover».
Esta es la forma más económica de configurar el balanceo a nivel de acceso de clientes. Dependiendo de los requerimientos de la organización se puede utilizar un balanceador externo, en este sentido los balanceadores de Kemp son muy sencillos de configurar y dependiendo de los requerimientos pueden ser relativamente económicos. La diferencia si utilizáramos un balanceador es que en lugar de tener 2 registros con el mismo nombre utilizaríamos 1 apuntando a la IP virtual del balanceador.
Configuración de servicios
Una vez definidos los nombres a utilizar, en nuestro caso «mail» y «autodiscover» configuramos cada uno de los servicios. En este caso todos utilizan HTTPS (por lo que debemos solicitar en el firewall abrir el puerto 443 TCP).
Para esto en el laboratorio configuramos las URLs internas y externas con el mismo nombre «webmail.dominio.com» (aprendiendoexchange.com y horuscs.com dependiendo del entorno).
Por otro lado configuramos el servicio de Autodiscover interno utilizando el FQDN «Autodiscover.dominio.com». Este en caso de clientes unidos al dominio se accedería mediante lo que se conoce como SCP (Service Connection Point, esta información se almacena en la partición de configuración de Active directory). En el caso de clientes que se conectan desde Internet deben poder localizar el servicio de Autodiscover mediante una consulta en DNS.
Si bien el acceso al correo (o al servicio de autodiscover interno) puede utilizar cualquier nombre por ejemplo «webmail», «mail», «correo», «owa», etc, para el caso de autodiscover a nivel externo se deben seguir ciertas reglas, la forma más sencilla es mediante el uso del nombre «autodiscover.dominio.com» donde «dominio.com» se corresponde al dominio de correo que usa el usuario. Es decir que si tenemos usuarios que utilizan en la dirección de correo primaria «@dominioA.com» y usuarios que utilizan «@dominioB.com» lo más sencillo sería agregar un registro «autodiscover» en cada zona de dominio: «autodiscover.dominioA.com» y «autodiscover.dominioB.com».
Certificado
En este punto tenemos los nombres y la configuración de los distintos servicios, en sí no importa el orden en el que se configure esto.
El tema que debemos resolver ahora es el certificado, la recomendación es utilizar un certificado público, en el caso del laboratorio utilizamos un certificado emitido por una CA (entidad certificadora) interna instalada en un DC.
En este certificado debemos incluir los nombres que usemos para acceder a los distintos servicios, esta configuración es crítica si queremos que los usuarios se conecten sin problemas.
El procedimiento de configuración es el mismo independientemente del tipo de certificado que usemos, la diferencia es donde procesamos el archivo con la solicitud (CSR). En nuestro caso lo procesamos con la CA interna pero en producción lo vamos a procesar con una CA externa como por ejemplo Godaddy o Digicert.
Salida de correo
Para el caso del envío de correo a Internet debemos configurar un conector y configurar los servidores correspondientes. Para tener alta disponibilidad a este nivel al menos 2.
Los servidores que envían correo a Internet podrían hacerlo directamente o podrían enviar a través de un smarthost y este último conectarse hacia Internet.
Si los servidores envían directamente (como configuramos en el laboratorio) estos deben tener habilitado en el Firewall la salida de SMTP (puerto 25 TCP), lo otro que deben tener es resolución de nombres externa . En Clientes usualmente esta resolución de nombres la encontramos configurada en los DNS internos mediante «forwarders» (reenviadores). Si envían a través de un smarthost solo se requiere SMTP hacia estos.
Un error común en este sentido es encontrar la tarjeta de red de los servidores con Exchange con un DNS externo configurado. Esto no se debe hacer bajo ninguna circunstancia, la tarjeta de red debe usar un DNS interno, el de la zona de Active Directory.
Entrada de correo
En cuanto a la entrada de correo esto implica 2 tareas:
- Configurar al menos un registro MX en la zona externa de cada dominio de correo que usemos
- Configurar el puerto 25 TCP en el firewall, ya sea haciendo NAT a los servidores con Exchange o hacia el smarthost
En este sentido, en principio no debemos configurar nada en Exchange más allá de solicitar los puntos 1 y 2 a quien corresponda. En general el punto 1 lo manejamos con un proveedor y el punto 2 con quien administra el Firewall.
Sobre las pruebas de conectividad…
En cuanto a las pruebas de conectividad, por ahora utilizamos un cliente interno por lo que ni siquiera hemos configurado un dominio de correo externo (los usuarios están usando el dominio de correo predeterminado «@aprendiendoexchange.local» o «@horuscs.local»).
Antes de realizar las pruebas externas de conectividad vamos a configurar esto ya que si bien no tiene relación con alta disponibilidad, los clientes externos localizan el servicio de autodiscover en base al dominio de correo y la idea es emular un entorno lo más parecido posible a producción.
Próximos pasos
En este punto ya tenemos configurado el DAG, las bases de datos replicadas, el acceso de clientes balanceado y configurado de tal forma que los clientes pueden conectarse sin inconvenientes y sin alertas de certificado.
Por último, tenemos el conector hacia Internet configurado utilizando Mail01 y Mail02 como posibles orígenes de transporte. Esto en producción debería ser complementado configurando los registros MX en la zona DNS externa. En muchas empresas en este sentido se configuran varios registros apuntando a distintos enlaces si contamos con redundancia a este nivel.
En el próximo módulo vamos a introducir un tercer servidor ubicado en un sitio alternativo y ver la configuración necesaria para contingencia.