Introducción a contingencia en Exchange
Acceso no autorizado. Para acceder al contenido complete el registro haciendo clic aquí.
Sobre Exchange Native Data Protection…
Exchange Native Data Protection es el nombre que se le da al uso de un conjunto de características incluidas en Exchange para proteger los datos sin necesidad de recurrir a backups.
La realidad es que no es una solución muy utilizada On Premises ya que tiene requerimientos muy específicos a nivel de hardware, cantidad de réplicas de bases datos, operaciones, monitoreo, etc. En general estos requerimientos no son accesibles para cualquier organización y aparte es difícil que un cliente acepte la idea de dejar de hacer respaldos de Exchange. Por fuera de lo mencionado, este es el mecanismo que se utiliza para protección de datos en Office 365 (no hacen respaldos).
Esta puede ser una buena solución en organizaciones muy grandes con costos importantes en relación a actividades de respaldo y restauración.
Dado que implementar Exchange Native Data Protection no es un requerimiento común voy a mencionar las características involucradas para al menos tener una idea cuando uno lee documentación al respecto.
JBOD (Just a Bunch of Disks)
Estos son discos directamente conectados al servidor sin RAID. En este caso no se usa RAID pero se requiere el uso de una controladora con batería para cache.
La idea de utilizar JBOD es que la tolerancia a fallas sea mediante redundancia de copias replicadas en lugar de utilizar RAID y discos costosos.
Esto reduce la complejidad a nivel de configuración del almacenamiento y mejora la disponibilidad del servicio porque requiere más copias de una base de datos (o sea que en esta configuración precisamos más servidores).
Usar JBOD no aplica a la mayoría de las organizaciones, si bien habilita a usar buzones más grandes a menor costo, desde el punto de vista del almacenamiento introduce otro tipo de complejidad que debe ser tomada en cuenta a nivel de monitoreo y operaciones (los discos fallan y debemos estar preparados para esto).
En general en clientes uno encuentra discos protegidos con RAID lo que deriva en que se requieran menos copias de las bases de datos porque ya hay un cierto nivel de tolerancia a fallos.
Copias con retraso (lagged copies)
Imaginemos el siguiente escenario, se introduce un error lógico en una base de datos replicada dentro de un DAG.
Qué sucede en este caso?
El error se replica al resto de las copias y para recuperarnos es necesario recurrir a un respaldo. Esto también podría aplicar a un escenario donde se eliminó información o cualquier tipo de cambio no deseado. Siempre se va a replicar al resto de las copias.
Para protegernos de esta posibilidad podemos utilizar lagged copies o copias con retraso. Estas copias son bases con retraso en la aplicación de logs, es decir que los logs se replican de forma continua como en el resto de las copias pero en las lagged no se aplican hasta que no pase el tiempo configurado.
Single Item Recovery (SIR)
Esta característica nos permite garantizar que durante el tiempo configurado a nivel de retención de elementos (14 días de forma predeterminada) cualquier elemento modificado o eliminado sea retenido internamente. De esta manera podemos mantener el elemento original y recuperarlo sin recurrir a un backup.
In-place hold / Litigation Hold
Estas 2 características permiten retener elementos durante un período de tiempo determinado (o incluso indefinido), en general por cuestiones legales.
Litigation Hold retiene todos los elementos de un buzón por el tiempo que se encuentre habilitado.
In-Place Hold permite retener elementos en base a una consulta, es decir que únicamente retendría elementos que cumplan con una o más condiciones específicas.
Truncado de logs
Usualmente los logs son truncados al realizar un respaldo completo de una base. Este no sería el caso si utilizamos Exchange Native Data Protection, por lo que en este escenario tendríamos que evaluar alternativas.
Para esto podemos utilizar Circular Logging lo que permitiría truncar logs una vez hayan sido replicados al resto de las copias de una base. Estos logs no serían truncados si hay problemas para replicar logs a copias pasivas, por lo que se podrían a acumular y llenar el disco frente a una falla a este nivel.
Como alternativa a Circular Logging podemos configurar «TruncationLagTime» lo que permitiría truncar logs de cumplirse toda una serie de condiciones.
Implementación de DAG en Exchange
Acceso no autorizado. Para acceder al contenido complete el registro haciendo clic aquí.
Sobre la Demo
En este módulo empezamos a trabajar con el sitio de contingencia, específicamente con el servidor Mail03:
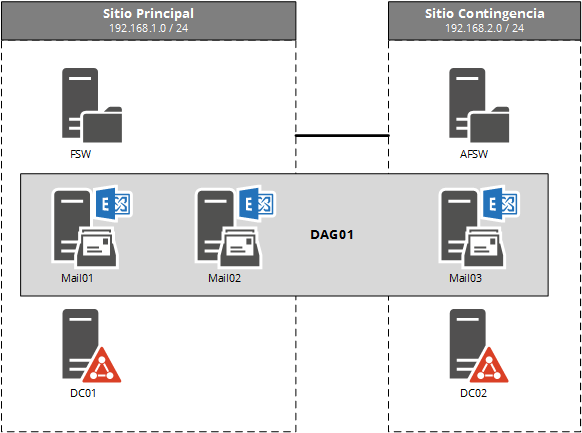
Sobre la configuración del servidor en contingencia…
El servidor ubicado en contingencia, en nuestro caso Mail03 en principio es configurado como cualquier otro miembro de DAG con las siguientes particularidades:
- Se configura el servidor para que este bloqueado de activación automática
- Las réplicas tienen un retraso, en el caso de la demo, 1 día
El servidor es configurado con el bloqueo de activación automático porque usualmente entrar en contingencia es un proceso manual. Por fuera de esto, si no hay ningún servidor disponible, Exchange podría intentar montar las bases aunque el servidor este configurado en «blocked». Como alternativa o en complemento, podemos usar el cmdlet Suspend-MailboxDatabaseCopy con el parámetro «ActivationOnly» sobre las réplicas en contingencia, de esta manera se continua replicando pero la activación estaría suspendida.
Esto no aplicaría en los casos que se desee failover automático entre sitios, específicamente en este caso sería requerido contar con la misma cantidad de nodos en cada sitio y un tercer sitio (o Azure) con un testigo configurado. Si bien hoy por hoy esta no es una configuración usual es algo a tener en mente.
En relación al retraso configurado en las réplicas en contingencia
Las bases en contingencia son configuradas con un retraso en la aplicación de logs de 1 día.
El motivo para haber configurado tan poco tiempo se debe a que usualmente no usamos las características asociadas a la copia con retraso, más bien el retrasar la aplicación de logs en contingencia funciona como un «seguro». Si pasa algo muy extraño y se replica a contingencia tenemos 1 día para notar la situación y descartar los logs.
En definitiva, en general configuro retraso en la aplicación de logs en contingencia para estar cubierto pero no porque sea común estar descartando logs o tareas de este tipo.
Modo DAC y el Split Brain Syndrome
Para entender bien la importancia de esto voy a comenzar con una anécdota.
Hace unos años en un Banco me solicitaron una revisión sobre la configuración de la implementación en Alta Disponibilidad y Contingencia de Exchange.
Por fuera del detalle, lo más relevante que se detectó fue que el modo DAC (Datacenter Activation Coordination Mode) estaba deshabilitado. Esto es así de forma predeterminada.
Los administradores no estaban familiarizados con el concepto y claramente tampoco la persona a cargo de la implementación, por lo que les digo algo así:
«Imaginemos que perdemos energía en el sitio principal»
«Ejecutamos el procedimiento manual para activar Exchange en contingencia»
«Los usuarios empiezan a trabajar en contingencia»
«Se restaura la energía en el sitio principal pero no así la conectividad entre sitios»
Qué pasaría en este caso?
Frente a este escenario lo que va a pasar es que los servidores con Exchange en el sitio principal van a tener quorum por lo que van a montar las bases. Esto es así porque usualmente en el sitio principal es donde está la mayoría de los votos.
Esto en qué deriva?
Supongamos que tenemos la DB1 activa en contingencia, esta misma DB1 va a estar activa también en el sitio principal.
En este caso vamos a tener usuarios conectados a la DB1 de contingencia y potencialmente usuarios conectados a la DB1 del sitio principal.
La DB1 del sitio principal ya no esta sincronizada con la DB1 del sitio de contingencia.
Ahora tenemos datos en la DB1 de un sitio y datos en la DB1 del otro sitio y ya no tenemos forma de consolidar automáticamente estos datos. En consecuencia tenemos que elegir que base va a funcionar como «autoritativa» y que base vamos a descartar (y posteriormente hacer el re sembrado de la base). Pero antes tenemos que tener en cuenta que de esta manera podemos perder información. Antes de descartar una base sería necesario exportar de algún modo las diferencias en relación a la otra base y luego ver como combinar la información.
Este trabajo se presta para la pérdida de información, aparte de ser un proceso manual y tedioso.
Qué me dijo el cliente?
«Es imposible que nos pase esto, tenemos UPS, generadores, etc, etc.»
Por este motivo decidieron dejar la configuración intacta mientras «evaluaban» si realmente tenía sentido hacer un cambio.
Qué paso después?
A las 48hs de tener la conversación sobre la gravedad de tener el modo DAC deshabilitado el Cliente perdió energía en el sitio principal, hubieron problemas con los generadores y activaron contingencia.
Sin darse cuenta al par de horas se reanudaron los servicios en el sitio principal pero no a nivel de WAN.
Esto terminó en bases partidas con Split Brain Syndrome. Me llamaron de urgencia y comenzamos con las tareas asociadas a la recuperación.
Por increíble que parezca esto realmente pasó. Inmediatamente resuelta la situación habilitamos el modo DAC y se avanzó con el informe de lo sucedido.
Muchas veces la diferencia entre una implementación profesional de una vamos a llamarle «improvisada» es un solo seteo…
…pero cuánto vale este seteo?
Volviendo al modo DAC…
En definitiva, la moraleja es habilitar el modo DAC siempre.
Si bien esperamos al módulo de contingencia para ver este tema, recomiendo habilitar el modo DAC en cualquier DAG independientemente de si tiene nodos distribuidos geográficamente o no. Incluso con un único sitio se pueden presentar situaciones específicas donde se podría terminar con el Split Brain Syndrome. Por fuera de esto, en general cuando se habla de modo DAC se habla de múltiples sitios ya que fue para lo que se diseñó en primera instancia.
Habilitar el modo DAC es tan simple como configurar en «dagonly» el parámetro «DatacenterActivationMode» de un DAG. Este simple seteo nos habilita a usar todos los cmdlets de recuperación que vamos a ver en la lección 3 de este módulo.
Cómo el modo DAC previene el Split Brain Syndrome ?
A partir de que se habilita el modo DAC, los nodos antes de poder montar una base de datos deben obtener permiso. Esto independientemente de que haya quorum.
Para controlar el montado de las bases en un DAG con modo DAC habilitado usamos el protocolo DACP.
El protocolo DACP básicamente es un bit que puede estar en 0 o en 1. Cuando el Active Manager inicia, este bit se encuentra en 0, lo que indica que no puede montar las base. Para que el DACP pase a 1, el nodo primero debe poder comunicarse con el resto de los miembros del DAG y alguno debe responder con el bit en 1, esto significa que puede montar las bases.
Volviendo a la anécdota del Banco con las base en Split Brain, si el DAG hubiera estado configurado con el modo DAC habilitado, al restaurarse la energía en el sitio principal, a pesar de tener mayoría de votos (teniendo quorum) las bases no habrían montado debido a que ninguno de los servidores habría tenido el bit en 1.
De esta manera se habría evitado la condición de split ya que la base solo habría quedado activa en contingencia.
Activación de sitio de contingencia
Acceso no autorizado. Para acceder al contenido complete el registro haciendo clic aquí.
Algunas dudas que pueden surgir sobre la demo…
Por qué configuramos el dominio de correo externo en esta lección?
El dominio de correo público lo debemos configurar en cualquier organización de Exchange que se utilice para enviar / recibir correo externo. Esto no tiene relación con Alta Disponibilidad o Contingencia.
El tema esta en que en el entrenamiento aparte de usar un cliente interno usamos un cliente externo simulando una conexión desde Internet. Hasta el momento no hemos probado el acceso externo por lo que no cambiaba la situación si configurábamos o no el dominio de correo externo.
Por qué lo precisamos en esta lección?
Específicamente por la prueba de conectividad desde el cliente externo.
El cliente al no estar dentro del dominio, la única forma que tiene de localizar el servicio de Autodiscover es mediante DNS.
Autodiscover es el servicio que devuelve información de las URLs y los distintos servicios en uso en Exchange. Esto tiene que funcionar bien independientemente de si se cuenta o no con alta disponibilidad (y es uno de los errores más comunes a nivel de configuración).
La forma más sencilla de localizar el servicio desde Internet es usando el siguiente FQDN:
autodiscover.dominio.com
Donde «dominio.com» se corresponde al dominio de correo primario del usuario.
Por ejemplo en nuestro caso, en la demo con Exchange 2013, el dominio interno es «aprendiendoexchange.local» mientras que el externo o publico es «aprendiendoexchange.com».
En el DNS externo tendríamos que tener registros para la zona aprendiendoexchange.com (no para .local).
Por este motivo configuramos el dominio de correo externo en esta lección, para que el cliente «externo» pueda localizar el servicio de autodiscover usando el FQDN:
autodiscover.aprendiendoexchange.com
Si no configuramos el dominio de correo, el cliente intentaría «autodiscover.aprendiendoexchange.local» y esto daría error por 2 motivos:
- Porque públicamente no existiría la zona «.local» o sea que desde internet no encontraría el registro
- Porque aunque si por algún motivo pudiera resolver el nombre, daría error de certificado ya que en este incluimos el nombre «autodiscover.aprendiendoexchange.com»
Sobre el testigo alternativo
En varios foros he encontrado que muchas veces se toma que el testigo alternativo se usa cuando no se encuentra disponible el testigo principal.
Esto no es así…
El testigo alternativo es utilizado en escenarios de recuperación de un sitio. Al no estar el testigo principal disponible (porque se encuentra en el sitio inoperativo) se le indica al DAG que utilice el alternativo.
Es decir que no hay ningún tipo de «failover» automático entre testigos.
Para qué usamos todos los parámetros «skip…algo» para activar las bases en contingencia?
Porque frente a la pérdida del sitio principal es posible que no este todo 100% saludable en el sitio de contingencia, por ejemplo a nivel de indice o que falte algún log por replicar.
Independientemente de estos «detalles» nuestra intención es lograr montar las bases en contingencia y lo más probable es que la información que falte en los logs se recupere desde Safety Net o cuando se recupere el sitio principal.
En definitiva, podemos usar directamente estos parámetros «skip algo» o en el caso de que el comando move-activemailboxdatabase de algún error (en este escenario diría que el 99% de las veces) . Esto mismo aplica al parámetro mountdialoverride.
Sobre el acceso de clientes
En la implementación usamos el modelo «unbound» es decir que usamos el mismo espacio de nombres en ambos sitios (principal y contingencia). Si la conectividad entre los sitios es buena seguramente no nos afecte que los usuarios externos se conecten a través de uno u otro.
Pero qué pasa si ambos sitios están conectados entre sí por un enlace lento?
En este caso «depende», si tenemos pocos usuarios externos quizás no sea un problema, pero en caso contrario las opciones más comunes son las siguientes:
- Tener un único registro externo para «mail» y «autodiscover» apuntando al sitio principal con un TTL lo más bajo posible (5 minutos recomendado). En este caso frente a la activación de contingencia debemos ir y modificar manualmente los registros externos para apuntar a la IP del sitio alternativo.
- Usar algún tipo de servicio que permita apuntar nuestros registros a un proveedor y en este configurar que en situaciones normales se apunte a la IP del sitio principal pero en caso de que no responda que apunte a contingencia. Dependiendo del proveedor el nombre de la solución, entre otros Amazon ofrece este servicio.